Disentangled Explanations for Neural Network Predictions on Audio Data
How do neural networks make decisions about music? This work unveils the hidden reasoning behind audio classification models by decomposing their predictions into interpretable, disentangled concepts—making the black box transparent.
By combining Disentangled Relevant Subspace Analysis (DRSA) [1] with Layer-wise Relevance Propagation (LRP) [2], we extract concept-based explanations that reveal what a neural network listens to when classifying music genres. Unlike traditional pixel-level explanations, our approach transforms complex time-frequency representations into listenable audio segments, allowing humans to literally hear what the model hears.
Master's Thesis | Machine Learning Group, TU Berlin
Supervised by Prof. K. R. Müller and Dr. Grégoire Montavon
Explore Results
Dive into interactive examples and listen to what the model hears.
Abstract
As nonlinear Machine Learning (ML) models are increasingly used in various real world applications, their black-box nature hinders in-depth model evaluation, apart from performance measures. In response, the field of Explainable Artificial Intelligence (XAI) has made much progress. It aims to reveal the rationale behind complex ML models, often by assigning relevance scores to model parts and input features, e.g., pixels. However, in some domains such as audio processing, where data—like time or time-frequency representations of amplitudes—is of rather unintuitive nature, the extracted explanations can be hard to grasp for humans. Suitably, a novel sub-field in the realm of XAI has emerged in very recent time that aims to decompose explanations into multiple sub-explanations, representing distinct decision concepts. These approaches offer a promising foundation to gain more valuable insights into models and the data domain, especially when dealing with complex data scenarios. This study targets the extraction of concept-based explanations for a neural network applied to audio classification tasks, by utilizing the newly proposed method, Disentangled Relevant Subspace Analysis (DRSA), in combination with Layerwise Relevance Propagation (LRP).
Research Methodology
- Conceptualization and training of a Deep Learning (DL) approach to solve audio classification tasks on inputs in time-frequency domain. The tasks are solved with a Convolutional Neural Network. The main showcase is conducted on a Music Genre Recognition (MGR) task on the GTZAN dataset [3].
- Explanation of model decisions on a local basis by utilizing the backpropagation-based XAI method LRP [2].
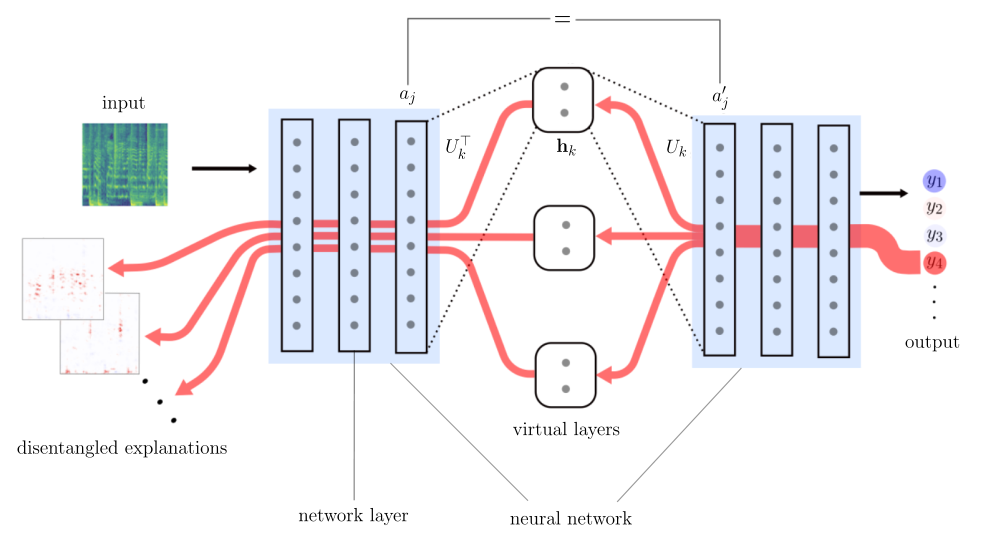
- Subsequently, relevant subspaces are optimized in latent space of the network with the newly proposed concept-based XAI method DRSA [1]. By implementing a two-step attribution that allows to condition relevances on single subspaces while propagating those from the outputs to the inputs, concept-based explanations can be visualized in the input domain. This process is schematically depicted in the figure below.
- Design of a methodology to transform explanations in time-frequency space into listenable audios to maximize human interpretability of those.
- Qualitative and quantitative evaluation of the extracted disentangled explanations to demonstrate the advantage of concept-based explanations and the enhanced explanatory value obtained through the application of DRSA. To provide a solid basis for evaluation, a synthetic dataset is created that fits the purpose of this study.
References
- Pattarawat Chormai et al. "Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces". In: IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
- Sebastian Bach et al. "On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation". In: PLOS ONE 10.7 (July 2015)
- G. Tzanetakis and P. Cook, "Musical genre classification of audio signals," in IEEE Transactions on Speech and Audio Processing, (July 2002)